Fnlwgt что это
Время прочтения: 7 мин.
Часто наборы данных, с которыми приходится работать, содержат большое количество признаков, число которых может достигать нескольких сотен и даже тысяч. При построении модели машинного обучения не всегда понятно, какие из признаков действительно для неё важны (т.е. имеют связь с целевой переменной), а какие являются избыточными (или шумовыми). Удаление избыточных признаков позволяет лучше понять данные, а также сократить время настройки и обучения модели, улучшить её точность и облегчить интерпретируемость. Иногда эта задача и вовсе может быть самой значимой, например, нахождение оптимального набора признаков может помочь расшифровать механизмы, лежащие в основе проблемы, представляющей интерес для исследования. Это может быть полезным для разработки различных методик, например, банковского скоринга, поиска фрода или медицинских диагностических тестов. Обычно методы отбора признаков делят на 3 категории: статистические методы или фильтры (filters), встроенные алгоритмы (embedded algorithms) и методы обёртки (wrappers). В настоящем цикле статей приведён обзор некоторых из этих методов с обсуждением их достоинств, недостатков и особенностей реализации.
Статистические методы (фильтры)
Статистические методы применяются до обучения модели и как правило имеют низкую стоимость вычислений. Они основаны на визуальном анализе (например, удаление признака, у которого только одно значение, или большинство значений пропущено), оценке признаков с помощью какого-нибудь статистического критерия (дисперсии, корреляции, и др.) и экспертной оценке (удаление признаков, которые не подходят по смыслу – например, «цвет галстука заёмщика» в задаче кредитного скоринга ��).
Простейшим способом оценки пригодности признаков является разведочный анализ данных (например, с библиотекой pandas-profiling). Однако при больших размерах датасета сложность этой процедуры значительно возрастает, поэтому её можно автоматизировать с помощью библиотеки feature-selector, которая отбирает признаки по следующим параметрам:
- Количество пропущенных значений (удаляются признаки, у которых процент пропущенных значений больше порогового значения)
- Коэффициент корреляции (удаляются признаки, у которых коэффициент корреляции больше порогового значения)
- Вариативность (удаляются признаки, состоящие из одного значения)
- Оценка важности признаков с помощью lightgbm (удаляются признаки, имеющие низкую важность в модели lightgbm. Следует применять только если модель lightgbm имеет хорошую точность)
Хороший туториал по этой библиотеке находится здесь.
Более сложные методы автоматического отбора признаков реализованы в sklearn. VarianceThreshold отбирает признаки, у которых дисперсия меньше заданного значения. SelectKBest и SelectPercentile оценивают взаимосвязь предикторов с целевой переменной используя статистические методы, позволяя отобрать соответственно заданное количество и долю наилучших признаков. Методы отбора основаны на F-тестах (обозначаются f_regression и f_classif соответственно для регрессии и классификации), оценке функции взаимной информации (mutual_info_regression и mutual_info_classif) и (chi2 для классификации). F-тесты хорошо работают только с линейными зависимостями, поэтому лучше всего они подойдут для линейной регрессии, а — тесты требуют неотрицательных и правильно отмасштабированных признаков. Поэтому удобнее всего использовать методы, основанные на вычислении взаимной информации – они почти не требуют настройки и позволяют находить нелинейные связи.
Рассмотрим применение статистических методов в реальной задаче – предсказать, зарабатывает ли человек больше $50 тыс. Загрузим библиотеки и данные, для удобства оставив только численные признаки:
- age – возраст,
- fnlwgt (final weight) – примерная оценка количества людей, которое представляет каждая строка данных,
- educational-num – длительность обучения,
- capital-gain – прирост капитала,
- capital-loss – потеря капитала,
- hours-per-week – количество рабочих часов в неделю.
Посмотрим на данные:
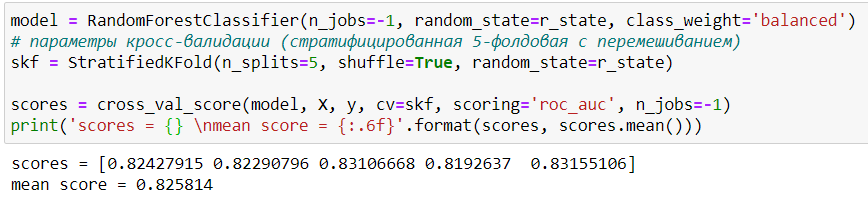
В качестве модели будем использовать случайный лес. Посмотрим точность на кросс-валидации:
И на важность признаков в модели:
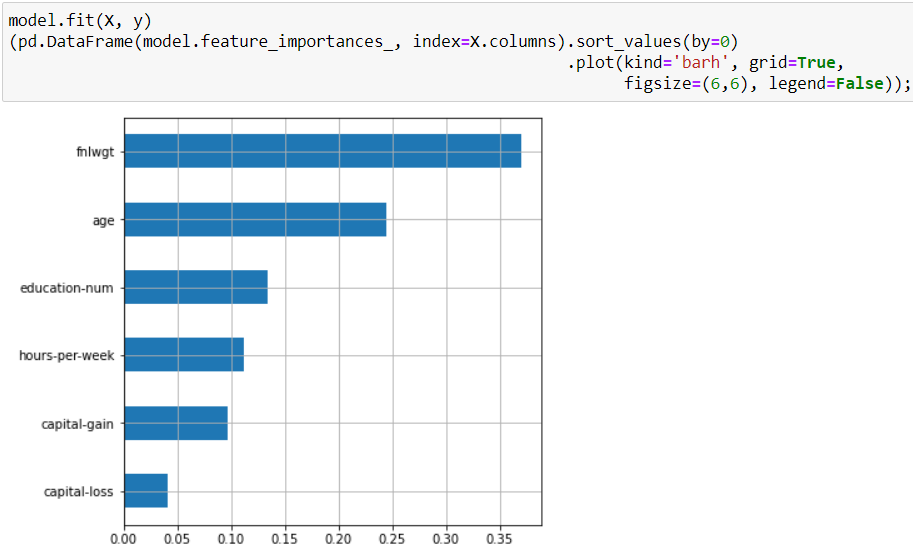
Самым важным признаком в нашей модели является fnlwgt. Это можно интерпретировать как то, что главным фактором того, что человек зарабатывает больше $50 тыс. является количество людей с такими же характеристиками. Такая интерпретация выглядит нелогичной, а происходит это потому, что деревянные модели (случайный лес и бустинг) могут выдавать сильно смещённую оценку признаков (подробнее здесь). При этом, чем хуже настроена модель, тем сильнее может быть смещение. Поэтому доверять оценке признаков таких моделей надо с осторожностью.
Создадим 12 «шумовых» признаков, элементами которых будут не коррелируемые случайные числа из выборок с нормальным и равномерным распределениями. Параметры каждого распределения подбираются случайным образом независимо друг от друга.
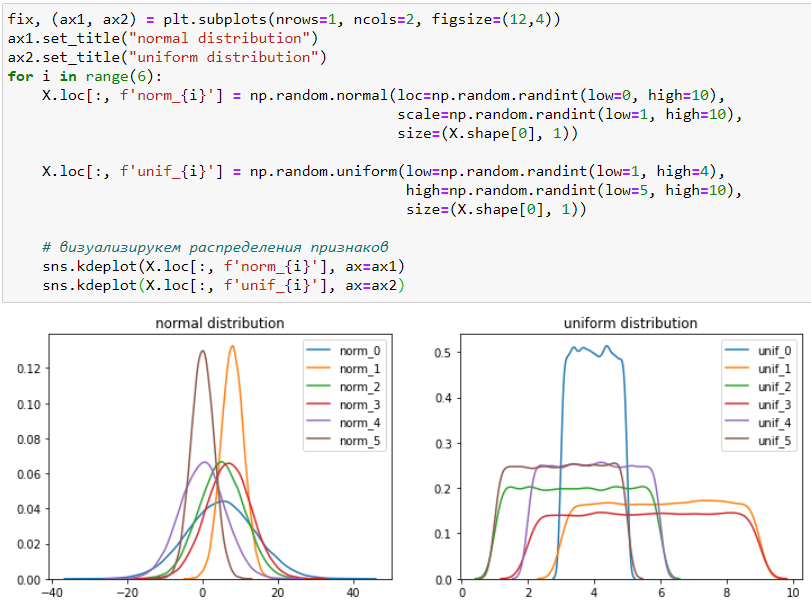
Проведём кросс-валидацию на наших зашумлённых данных и посмотрим на важность признаков:
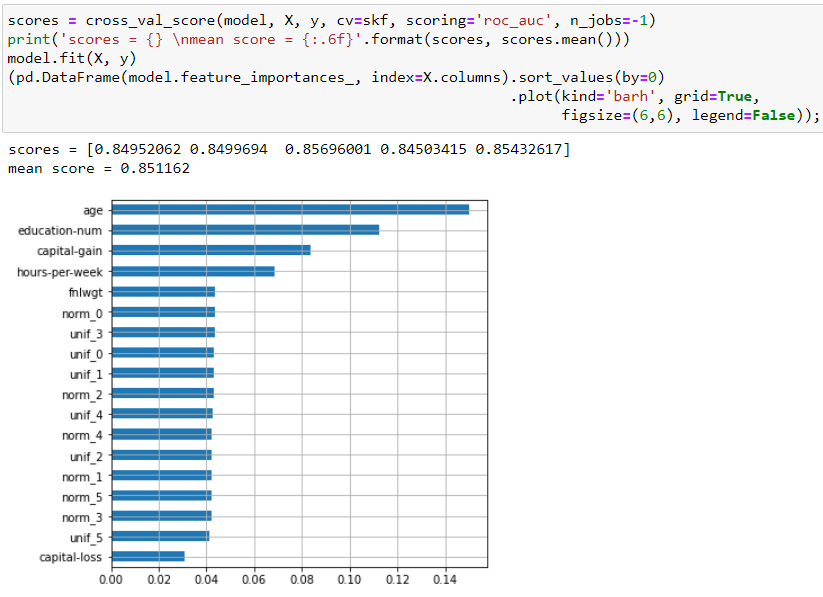
Несмотря на большое количество добавленных шумовых признаков, точность модели на кросс-валидации значительно возросла как на каждом фолде, так и в среднем! Кроме этого, шумовые признаки имеют высокую важность, сравнимую с двумя оригинальными признаками. Очевидно, что наша модель переобучена, однако в реальных задачах такие ситуации бывает очень сложно распознать, особенно когда при удалении некоторых признаков (про которые неизвестно – шумовые они, или нет) падает валидационная точность.
Проведём отбор признаков статистическими методами, для чего будем использовать обобщённый вариант SelectKBest и SelectPercentile, который называется GenericUnivariateSelect. Он принимает на вход 3 параметра – функцию оценки, режим отбора и его параметры. В качестве функции оценки будем использовать метод, основанный на вычислении взаимной информации.
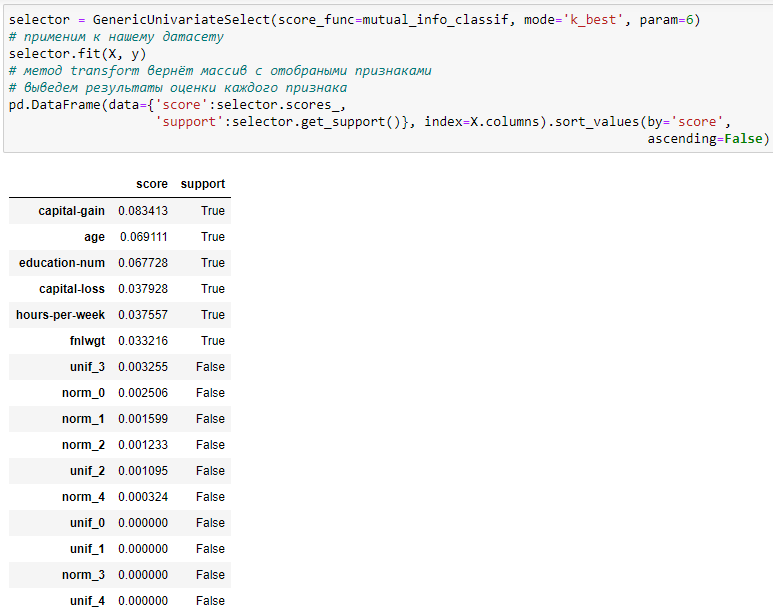
Сгенерированные нами признаки имеют низкое значение оценочной функции (scores_), поэтому в дальнейшем селектор не будет их использовать (get_support()=False).
В реальной задаче (когда количество шумовых признаков неизвестно) параметры GenericUnivariateSelect можно находить на кросс-валидации вместе с другими гиперпараметрами модели. Посмотрим, как изменится точность нашей модели после подбора параметров регуляризации случайного леса и количества признаков селектора:

Средняя точность на кросс-валидации значительно выросла, а лучший результат получился всего для 5 признаков. Посмотрим на них:
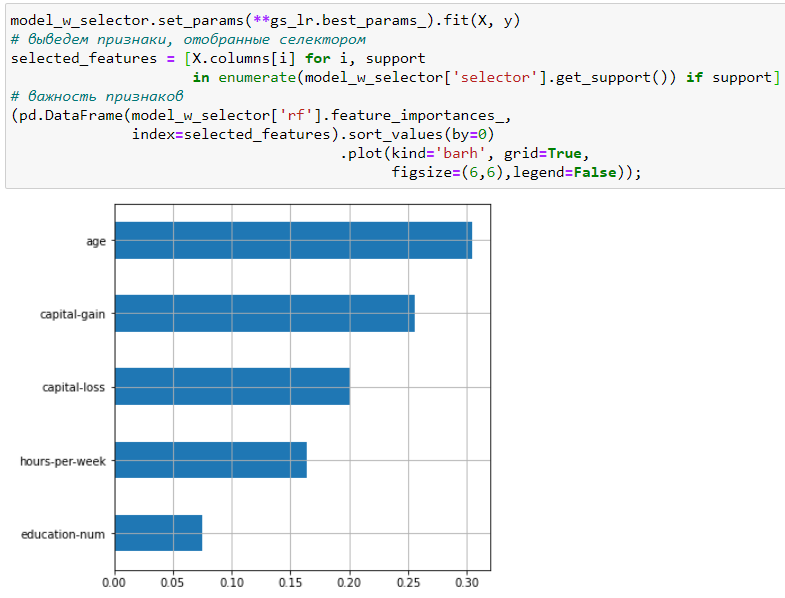
Таким образом лучший результат был получен после удаления шумовых признаков и признака fnlwgt, который при первоначальной оценке был самым значимым для модели. Однако из всех оригинальных признаков он имел наименьшее значение оценочной функции в GenericUnivariateSelect. Результаты оценки важности признаков после отбора имеют более логичную интерпретацию – на заработок человека влияют именно характеристики человека, а не параметры самой выборки. Таким образом статистический отбор признаков бывает полезен для увеличения точности модели и получения менее смещённой оценки для интерпретации её результатов.
Заключение
В статье были рассмотрены некоторые статистические методы отбора признаков. К их достоинствам можно отнести низкую стоимость вычислений (линейно зависит от количества признаков) и хорошую интерпретируемость. К недостаткам – то, что они рассматривают каждый признак изолировано, поэтому не могут выявить более сложные зависимости в данных, например, зависимость целевой переменой от нескольких предикторов. Кроме того, в некоторых случаях даже небольшое изменение признака (или наличие непустых значений) может быть само по себе очень важным, поэтому к результатам отбора следует относиться критически и по возможности проводить экспертный анализ. Ноутбук, приведённый в статье, доступен в моём репозитории. Более сложные методы отбора признаков будут рассмотрены в следующих статьях цикла.
How to reduce memory used by Random Forest from Scikit-Learn in Python?
The Random Forest algorithm from scikit-learn package can sometimes consume too much memory:
- max_depth=None ,
- min_samples_split=2 ,
- min_samples_leaf=1 ,
which means that full trees are built. Bulding full trees is by design (see Leo Breiman, Random Forests article from 2001). The Random Forest creates full trees to fit the data well. If there will be one tree in the Random Forest, then the model will overfit the data. However, in the Random Forest there are created set of trees (for example 100 trees). To overcome the overfitting (and increase stability) the bagging and random subspace sampling are used. (Bagging — selecting subset of rows for training, random subspace sampling — selecting subset of columns in each node split search).
In the case of large data sets or complex datasets, the full tree can be really deep and have thousands of nodes. Such single decision tree will use a lot of memory and thus the memory consumption of the Random Forest will grow very fast. In this post I will show how to reduce memory consumption of the Random Forest. In the example I will use Adult Income dataset.
Let’s load packages and the data
The dataset has 32,561 rows and 15 columns (including the target column). We see that data use about 3.8 MB in the memory (similar memory is also needed to store the data on the hard drive disk).
| age | workclass | fnlwgt | education | education-num | marital-status | occupation | relationship | race | sex | capital-gain | capital-loss | hours-per-week | native-country | income | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 39 | State-gov | 77516 | Bachelors | 13 | Never-married | Adm-clerical | Not-in-family | White | Male | 2174 | 0 | 40 | United-States | <=50K |
| 1 | 50 | Self-emp-not-inc | 83311 | Bachelors | 13 | Married-civ-spouse | Exec-managerial | Husband | White | Male | 0 | 0 | 13 | United-States | <=50K |
| 2 | 38 | Private | 215646 | HS-grad | 9 | Divorced | Handlers-cleaners | Not-in-family | White | Male | 0 | 0 | 40 | United-States | <=50K |
| 3 | 53 | Private | 234721 | 11th | 7 | Married-civ-spouse | Handlers-cleaners | Husband | Black | Male | 0 | 0 | 40 | United-States | <=50K |
| 4 | 28 | Private | 338409 | Bachelors | 13 | Married-civ-spouse | Prof-specialty | Wife | Black | Female | 0 | 0 | 40 | Cuba | <=50K |
The data needs preprocessing. We will fill the missing values with the most frequent values and convert categoricals into integers.
The first 14 columns will be used as input to the model. The last column income will be the target column.
Let’s use 25% of the data for testing and the rest for training.
I create the Random Forest Classifier with default parameters. This means that full trees will be built. There will be created 100 trees (the default of n_estimators ).
Let’s train the model:
Check the depth of the first tree in the Random Forest
Let’s check the depth of all the trees in the Forest:
Check the size of single tree in the disk after saving with joblib:
Our dataset size was 3.8 MB so the resulting Random Forest is about 13 times larger than the dataset! The dataset was pretty small, you can easily imagine how the Random Forest size will explode for larger files (the complexity of the dataset matters a lot because it determines the depth of the full tree).
Before changing anything in the Random Forest let’s check its performance.
Reduce memory usage of the Scikit-Learn Random Forest
The memory usage of the Random Forest depends on the size of a single tree and number of trees. The most straight forward way to reduce memory consumption will be to reduce the number of trees. For example 10 trees will use 10 times less memory than 100 trees. However, the more trees in the Random Forest the better for performance and I will search for other hyper-parameters to control the Random Forest size.
The simplest way to reduce the memory consumption is to limit the depth of the tree. Shallow trees will use less memory. Let’s train shallow Random Forest with max_depth=6 (keep number of trees as default 100 ):
Let’s save the shallow Decision Tree to the disk:
You see, the full single tree size was: 0.52 MB while the shallow tree size is 0.01 MB. Let’s save the whole forest:
The Random Forest with full trees has size 49.67 MB and the shallow Random Forest size is 0.75 MB so 66 times less!
Let’s check the performance of such shallow tree:
The perfomance is better! The shallow Random Forest has about 4% better logloss (the lower value the better). So we reduced the size of Random Forest by 66 times and increase the perfomance! 🙂
The shallow trees can be also obtained by tuning min_samples_split or min_samples_leaf (or even other hyper-parameters, like: min_weight_fraction_leaf , max_features , max_leaf_nodes ). However, I prefer to tune max_depth because it is more intuitive.
Extra tip for saving the Scikit-Learn Random Forest in Python
While saving the scikit-learn Random Forest with joblib you can use compress parameter to save the disk space. In the joblib docs there is information that compress=3 is a good compromise between size and speed. Example below:
Compressed Random Forest is 6 times smaller!
The same obervation about memory consumption should be valid for Extra Trees Classifier and Extra Trees Regressor .
sadhana1002/PredictingSalaryClass-Classification
Abstract: Predict whether income exceeds $50K/yr based on census data. Also known as «Census Income» dataset.
Listing of attributes:
age: continuous. workclass: Private, Self-emp-not-inc, Self-emp-inc, Federal-gov, Local-gov, State-gov, Without-pay, Never-worked. fnlwgt: continuous. education: Bachelors, Some-college, 11th, HS-grad, Prof-school, Assoc-acdm, Assoc-voc, 9th, 7th-8th, 12th, Masters, 1st-4th, 10th, Doctorate, 5th-6th, Preschool. education-num: continuous. marital-status: Married-civ-spouse, Divorced, Never-married, Separated, Widowed, Married-spouse-absent, Married-AF-spouse. occupation: Tech-support, Craft-repair, Other-service, Sales, Exec-managerial, Prof-specialty, Handlers-cleaners, Machine-op-inspct, Adm-clerical, Farming-fishing, Transport-moving, Priv-house-serv, Protective-serv, Armed-Forces. relationship: Wife, Own-child, Husband, Not-in-family, Other-relative, Unmarried. race: White, Asian-Pac-Islander, Amer-Indian-Eskimo, Other, Black. sex: Female, Male. capital-gain: continuous. capital-loss: continuous. hours-per-week: continuous. native-country: United-States, Cambodia, England, Puerto-Rico, Canada, Germany, Outlying-US(Guam-USVI-etc), India, Japan, Greece, South, China, Cuba, Iran, Honduras, Philippines, Italy, Poland, Jamaica, Vietnam, Mexico, Portugal, Ireland, France, Dominican-Republic, Laos, Ecuador, Taiwan, Haiti, Columbia, Hungary, Guatemala, Nicaragua, Scotland, Thailand, Yugoslavia, El-Salvador, Trinadad&Tobago, Peru, Hong, Holand-Netherlands.
Scope of this notebook
In this notebook, various classification algorithms are fed the training data (part of entire set) and the scores are compared. Just as a learning mechanism & to confirm how different algorithms work with adults dataset